









Using Redis for real-time analytics — the choice of many leading companies!

Smart and delightful customer experiences put great demands on the performance of interactive applications. This requires high-performance databases that can handle a wide variety of application scenarios with minimal complexity and cost, without compromising performance. Redis is exactly such a database, widely used by enterprises for real-time analytics.
High-Performance Business Drivers
Real-Time Analytics
In everyday life, when users interact with applications, the new generation of apps often tell users things like:
“We noticed you like X, we think you might also like Y.”
Or when users make a selection or a purchase, they receive suggestions like:
“Many of our users who chose A were happiest when they also chose C. We thought you should know.”
Or even:
“You just booked Q — here are some reviews for R, which you might want to check out afterward.”

These smart applications offer timely and contextually relevant suggestions while users are still engaged, providing opportunities to enhance user experience and satisfaction. Offers made at this moment are much more effective than cold emails or calls made days later.
This level of smart interaction also greatly enhances user experience — for instance, a user who just booked a ticket to “Second City Chicago” might appreciate being shown discounted dining options nearby before the show. From a business perspective, delivering a superior experience can retain loyal customers who might otherwise be lured away by competitors offering better service.
The “smartness” of an application can also include detecting unusual behaviors that signal various types of fraud, from gaming fraud to identity fraud or promotional abuse. Successful detection must happen before users finish fraudulent actions, which demands real-time behavioral analysis.

Thanks to the increasing availability of inexpensive computing power, data processing tools, and learning frameworks, integrating “intelligence” into applications is more achievable than ever. However, adding intelligence without sacrificing application performance or responsiveness is critical.
Especially for customer-facing applications, users expect responses within 100 milliseconds. Considering that Internet round-trip times can take up to 50 ms, the application must complete processing, data access, and response generation within 50 ms.

To meet this requirement at scale, the database must deliver sub-millisecond response times under any load. In addition, real-time analysis must happen at the same speed and in the same operations as transactional processing — meaning in-database analytics is essential.
Redis’ Analytical Capabilities
Redis is an in-memory database platform renowned for its high performance, extreme versatility of data structures, and modular extensibility for all types of processing, analysis, and storage use cases.
Performance:
Redis has been benchmarked to process one million operations per second with sub-millisecond latency on ordinary AWS instances. When it comes to end-to-end application throughput and latency, Redis easily outperforms every other NoSQL database on the market with minimal resource usage.

Data Structures:
The real power behind Redis’ analytics lies in its rich data structures: Sets, Sorted Sets, Hashes, Lists, Strings, Bitmaps, and HyperLogLogs. These structures not only allow flexible data storage but also provide built-in operations for performing complex in-memory analytics.
Example: Sorted Sets
Sorted Sets store members ordered by scores. Retrieving members by score range is trivial, making them ideal for time-series data, real-time bidding, purchase volume rankings, most viewed articles, highest scores, and more.
Thanks to their native implementation in Redis, Sorted Sets enable highly efficient operations like sorting, range queries, range counting, and set operations (intersection, union, etc.) — all performed with maximum simplicity and speed.
Using Sorted Sets for analytics, such as time-series analysis, can be 10–100x faster than using traditional key-value or disk-based databases.

Other Redis data structures offer similar capabilities for analytics:
-
Geo Data structures enable geospatial data analysis and distance calculation.
-
HyperLogLog offers probabilistic cardinality estimation with minimal memory usage even for millions of items.
Combined with features like Pub/Sub, key expiration, list operations (push, pop), and increment/decrement commands, Redis allows developers to assemble their applications like building blocks.
Redis also supports embedded Lua scripting, extending the complexity and scope of analytics you can perform natively inside Redis.
Redis Modules further expand Redis’ capabilities, including:
-
neural-redis: Native feed-forward neural networks
-
Redis-ML: Machine learning models as a Redis service
-
RediSearch: Full-text search and secondary indexing
-
ReJSON: JSON data manipulation
-
RedisGraph: Graph database capabilities
-
TopK, Count-Min Sketch, ReBloom: Probabilistic data structures for advanced analytics
Redis Use Cases in Transactions and Analytics
Modern smart applications rely on Redis for its ability to perform real-time transactions and analytics simultaneously, without compromising speed or functionality.
1. Personalized Recommendations
Personalization typically involves:
-
User profiles (history, location, demographics, preferences)
-
Business rules for offers (conversion goals, segmentation, behavior context)
Redis serves as the transactional store capturing user actions in real-time, while simultaneously enabling high-speed updates to user profiles and real-time calculations like counting, scoring, and ranking to trigger dynamic personalized offers — all with sub-millisecond latency.
Sorted Sets in Redis allow rapid similarity scoring, enabling the right recommendation to be presented instantly.
2. Machine Learning Predictions
For dynamic correlations within user behavior, machine learning models are often trained offline with frameworks like Spark or TensorFlow. However, traditional models stored on disk are too slow for real-time predictions.
Redis-ML allows you to store, retrieve, execute, and update machine learning models directly in memory, achieving the scale and speed needed for online inference within 50 ms.
It supports multiple ML models (Random Forests, Logistic Regression, Gradient Boosting Trees) and enables applications written in different languages to access models simultaneously.
For simple feed-forward neural networks, neural-redis provides an open-source Redis module for in-memory neural network operations.
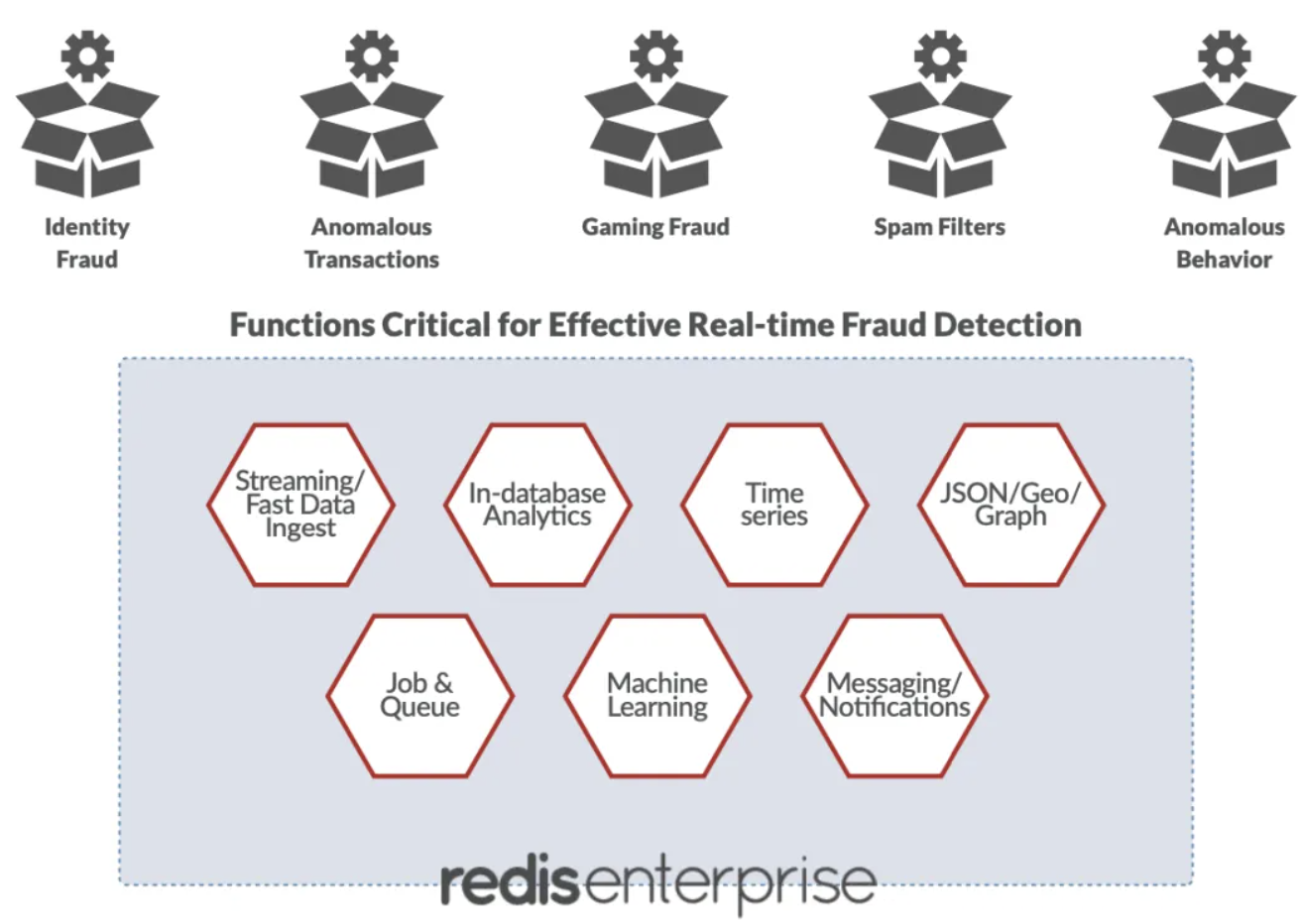
3. Fraud Detection
Fraud detection systems must process millions of data points and inline millions of customer transactions for maximum effectiveness.

Redis, with its:
-
High performance
-
Stream data processing (via Pub/Sub, Lists)
-
Built-in analytics (Sets, HyperLogLog)
-
Geospatial and graph analysis (Geo, RedisGraph modules)
becomes the natural choice for real-time fraud detection where application latency must stay within 100ms.
Fraud detection solutions benefit from Redis’ capabilities for:
-
Fast session updates (Hashes)
-
Queue/job management (Lists)
-
Immediate alerting and notification (Pub/Sub)
-
Integrated machine learning inference (Redis-ML)
“Using Redis Enterprise in our fraud detection services has been a phenomenal decision. It allowed us to manage tens of billions of transactions daily while scaling with our exponential growth, and speeding up fraud detection for all customers.” — Ravi Sandepudi, Engineering Lead, Simility
4. Interactive Reporting
When users interactively generate reports from millions of records, they expect data retrieval in 10ms and pagination in 3ms.
Large data stores cannot meet this need alone. Redis acts as a high-speed intermediate data store with pre-sorted Sorted Sets, enabling ultra-low latency even when handling millions of records.
Redis is often used alongside RDBMS and large NoSQL databases (e.g., HBase, Cassandra) to deliver high throughput and low latency user experiences.
Managing Terabytes of Data in Redis

Running in-memory, Redis faces two common challenges:
-
How to scale Redis
-
How to manage large volumes of data efficiently
Scaling Redis with High Availability:
-
Redis is single-threaded, but scales horizontally by sharding (partitioning data across multiple instances).
-
Redis can operate in persistent mode with multi-rack/region/datacenter/cloud replication for high availability.
Using Redis Enterprise software, you can create shared memory pools across a cluster of servers automatically for seamless scaling and high availability.