




 Tableau
Tableau





 Tableau
Tableau Minitab
Minitab




 Alteryx
Alteryx













 Neo4j
Neo4j










 Talend
Talend




















 华为云
华为云 腾讯云
腾讯云 IT/安全
IT/安全










如今,数据可视化和自然语言沟通共同影响着人们理解和传递信息的方式。虽然图表能高效展现复杂的数据变化,但在日常交流中,人们更倾向于用口头或书面语言描述数据趋势。
问题在于,这种表达方式经常带有主观色彩,不同的人对同一现象的理解和描述可能存在偏差,这给数据的准确传递和决策带来挑战。
针对这一现象,Tableau 研究团队开展了一项创新性研究,试图用量化的方法,将自然语言表达与具体的数据变化建立直接联系。这项研究成果不仅提升了数据解读的精确度,也为跨领域、跨文化的数据交流提供了更科学的基础。
接下来,本文将从理论探索到实践落地,详细介绍这一研究背后的原理、实施过程,以及对未来数据沟通与 AI 应用带来的价值和启发。
为何要量化自然语言描述?
数百年来,可视化始终是数据分析的首选方式,这是有原因的:它能通过“高带宽渠道”同时呈现多维度数据,既利用了人类与生俱来的感知能力,又基本不受语言和文化差异影响。
事实上,预计到 2030 年,数据可视化工具的市场规模将达到 220 亿美元。这足以说明,人们确实喜欢观察自己的数据。此外,无论是用手语、口语、文字还是短视频,大家同样热衷于讨论数据。我们通过电视收看新闻,阅读书籍报刊,互相传递世界动态。
然而,尽管自然语言足够细腻,甚至能让 Toni Morrison(美国著名作家,曾获得诺贝尔文学奖,其文学作品以精准细腻的语言、深入人心的情感描写而闻名)描绘出最微妙的情感差异,却依然难以有效解释海量数据。
试想一下,仅通过口头描述一个简单的散点图或柱状图需要多久?显然在高效理解精确数据方面,可视化更有优势。毕竟,那 220 亿美元可视化预算的大部分,都是为了帮助人们精准、高效地理解关键数据,比如失踪人口、气候变化、企业利润率,以及疾病暴发情况等。
以突发公共卫生事件举例:
在新冠疫情期间,医院需要准确预测感染人数以及合理安排医护人员的比例,这种精确度甚至要细化到小数点后一位,因为任何误差都可能危及生命。
反观普通大众是如何获取新冠数据的呢?大多数家庭的做法是通过新闻报道了解趋势,关注感染人数是上升还是下降,本地病例是否激增、趋于平稳或有幸回落。
虽然每个人都关心具体数字,但简明易懂的趋势描述通常已经足够指导日常生活:
👉 新冠病例趋势稳定?送孩子上学。
👉 病例增加?出门戴口罩。
👉 病例激增?那还是乖乖待在家里追剧吧。
这些思考,正是 Tableau 研究团队着手量化自然语言描述的原因。如果能将数据转化为既易于理解又足够精确的自然语言描述,使之成为人们采取行动或获取洞见的可靠依据,那么它将成为数据分析的绝佳媒介。
如何为词汇赋予数值?
像“稳定”、“激增”、“缓升”这样的词汇,本身就带有一种半量化的意味。比如,对你来说:
“稳定”意味着“与之前差不多”;
“激增”代表“大幅上升且当前水平远超以往”;
“缓升”则是指“略微高于之前且持续攀升,明日可能更高”。
这些词汇告诉我们某件事正在如何变化,甚至还能预估未来的发展趋势。
同时,它们还暗示着某种形态。比如"峰值/波峰"通常意味着先上升后回落(有时可能指正处于上升阶段尚未回落)。此外,波峰振幅往往显著大于常规波动区间,但具体差异幅度如何界定?是 10%?100%?还是 63%?不同人对此可能有不同理解。
所以,如果想让这些词汇表达得更准确,或希望让计算机也能像人一样正确理解这些词,最直接的办法就是展开调研,询问人们对这些词的理解,然后达成一个共识,以便把这种语言感受转化为可量化的标准。
如图 1 ,为了收集人们对可视化形态的认知,Tableau 研究团队开发了一个网页应用,并邀请用户对一组随机生成的折线图形状进行描述,每种形状由连在一起的七段线段构成。参与者可将左侧词库中的词汇拖拽至右侧对应形态完成标注,系统会自动将标签吸附至最相近的线段。
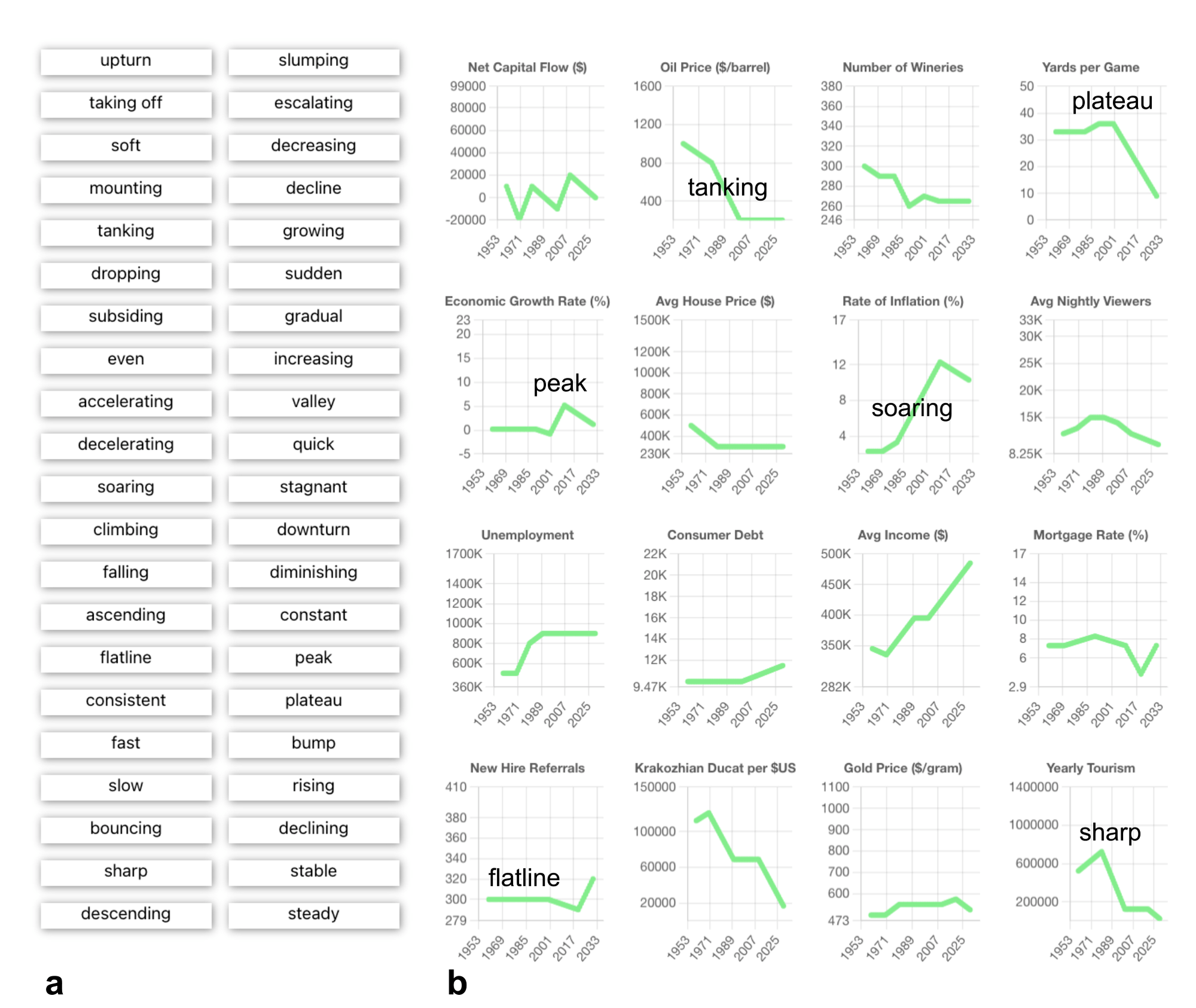
图1:折线图语义标注收集工具界面
参与者将左侧词汇 (a) 拖拽至右侧图表特征 (b) ,词汇会自动吸附至最近图表位置。已完成标注的词汇可随时移动或删除,同一词汇可重复用于多个图表或同一图表不同位置。
通过这个工具,Tableau 研究团队收集到了海量优质数据(如图 2)。分析的第一步,是观察哪些词汇会被一起用来描述同一个线段,也就是所谓的“共现”关系。
图2:折线图语义标注收集数据表
Tableau 研究团队的设想是,被不同参与者标注在同一线段的共现词汇,可能反映着群体对词义的共识理解。
如图 3,右侧区域展示了两个聚类维度:左列呈现高频共现词汇组合表,比如“激增”常与“峰值”、“攀升”同时出现;右列则基于标签共现性进行层次聚类,最终呈现出五个主要聚类群组,其中三个与“平稳”、“上升”、“下降”的概念高度吻合。
接下来,进一步分析标注线段的斜率特征(每个图形均由七段连续折线构成)。通过计算各标签对应线段区间的平均斜率,研究团队发现了数据呈现与认知直觉高度温度的规律。
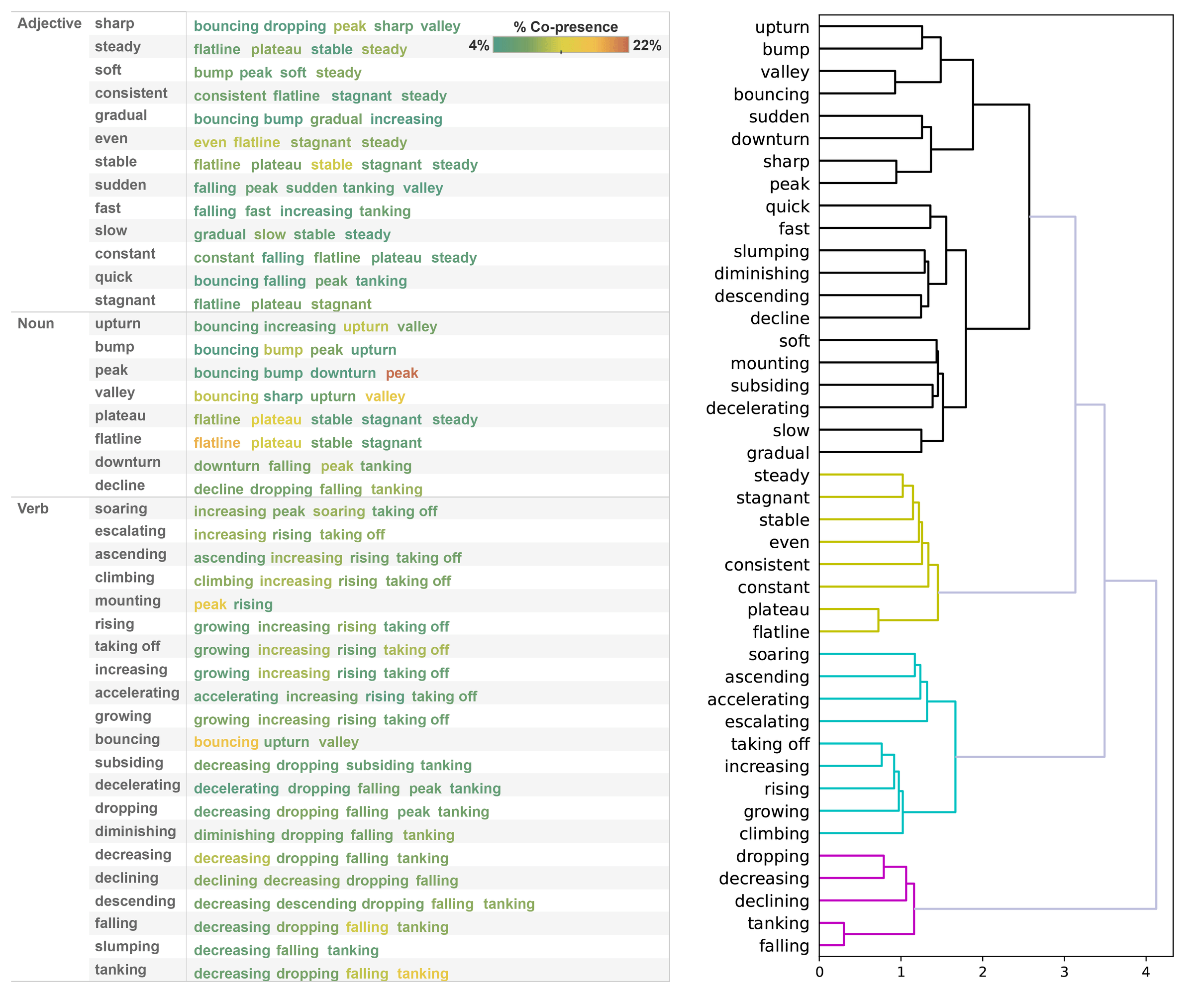
图3:Tableau 标注共现表与聚类树图
如上图,初步建立的语义层级显示:“暴跌”的负斜率明显比“下跌”更为陡峭;相比代表平稳趋势的“持平”(图表中间的零斜率基线代表完全平稳状态),“下降”的负斜率更大;沿着趋势等级往上,正斜率呈现出从“增长”到“起飞”,最终达到“飙升”的递进关系。
当这张图表呈现眼前时,团队全员都为之振奋!数据中清晰可辨的信号不仅能够被测量和量化,更将在未来数据分析中发挥实用价值。
如何用斜率数据做标注?
假设,你正在分析股票市场数据,想在分享给同事前准确标注关键节点。当股价暴跌 80% 时,这算是“跳水”、“崩盘”还是“渐进回调”?这类模棱两可的语义,正是要解决的难题。
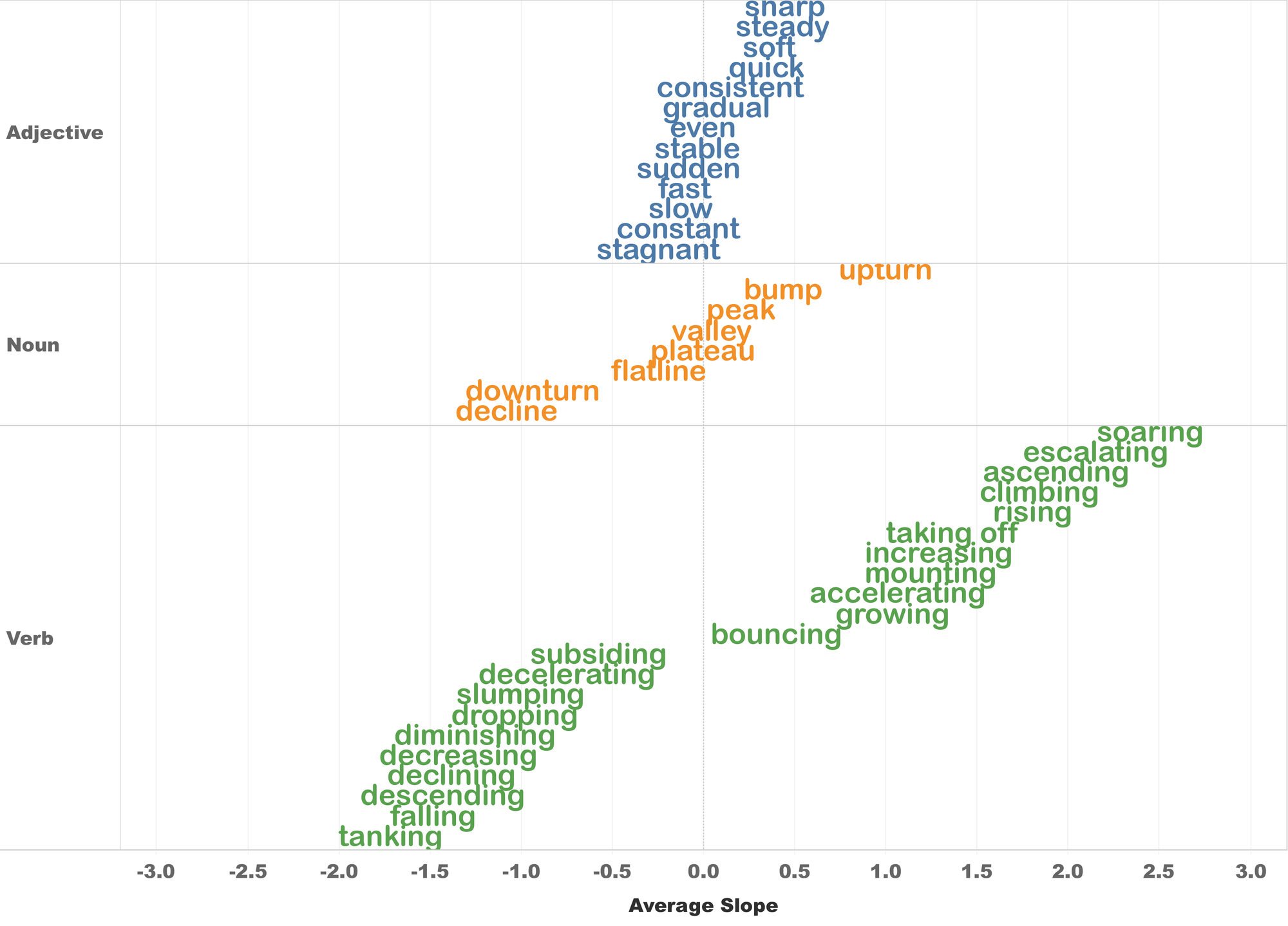
图4:折线图平均斜率标注图谱
于是,Tableau 研究团队将问题拆解为两个维度——形态识别与斜率识别。
👉 在形态识别方面,他们采用了类似数字信号处理(DSP)的思路:通过互相关(cross-correlation)的滑动窗口技术,将预定义形态与输入数据进行逐点相似度比对。简单来说,就是把目标形状沿着输入数据逐步滑动,来计算两者的相似度得分。
当形态与数据差异显著(比如输入数据是一条平直的线,而待识别形状却是断崖式下跌),相似度得分较低;当两者高度吻合(比如都表现为断崖特征)是,得分就会较高。最终,选取相似度得分最高的预定义形态,并用它们对应的标签来标记输入数据。
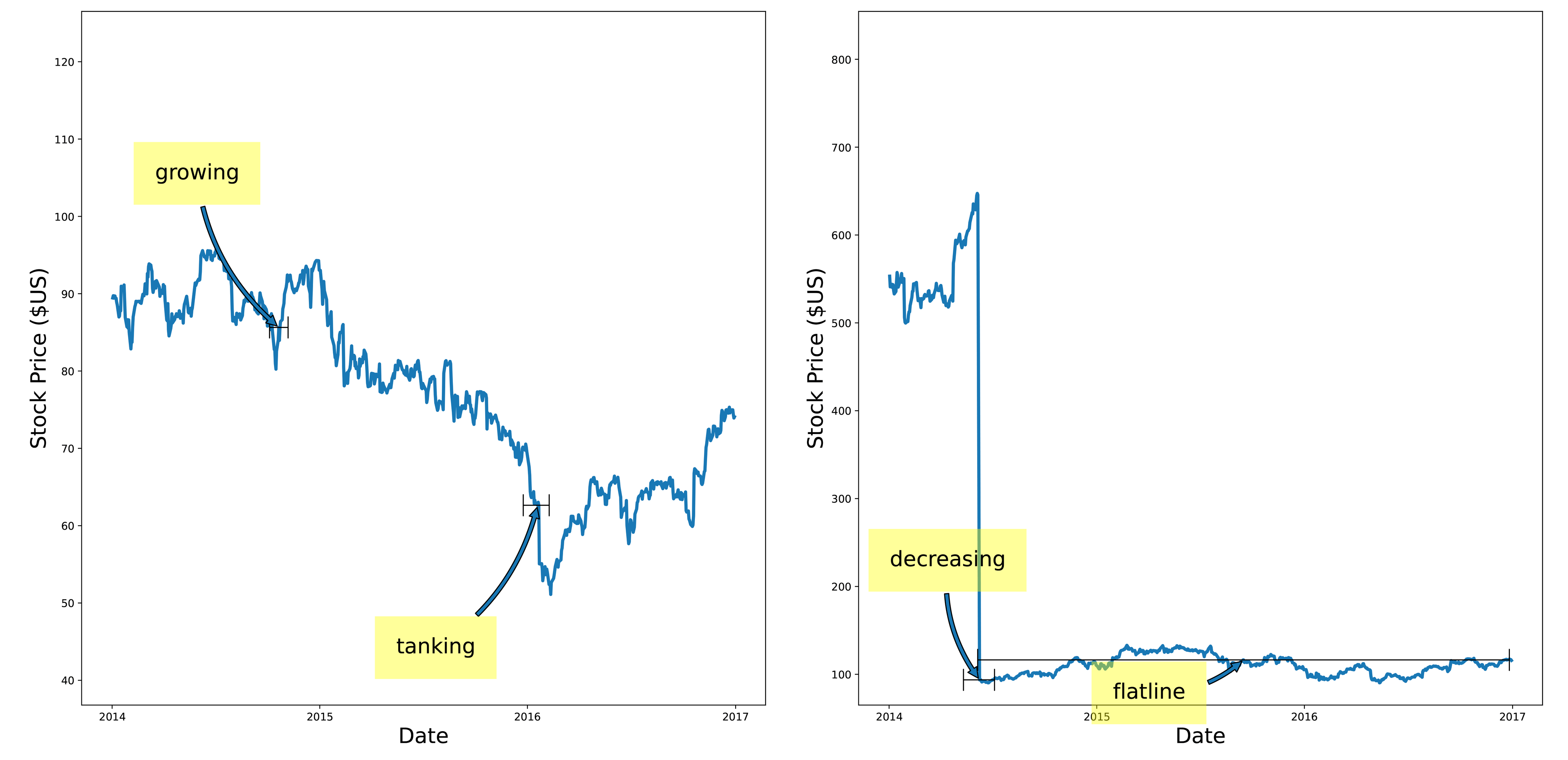
图5:折线视觉特征标注结果示意图
如上图所示,这一算法成功识别出“增长”(growing)、“崩盘”(tanking)、“下降”(decreasing)、“企稳”(flatline)等特征区域。
👉 斜率识别的方法则稍有不同。回想一下,在之前用于数据收集的网页标注工具中,每个预定义的折线形态由七个带标签的线段构成,且每个线段都有对应斜率。
基于此,研究团队建立了“斜率与标签对照词典”(详见图 6)。
比如,当输入数据中的某段斜率约为 1.2 时,查询词典可知其对应的是“增长”(increasing)标签;斜率为 -1.7 则标记为“崩盘”(tanking)。这样一来,只需把输入的数据拆解成多个线段,计算出每段线段的斜率,再到“斜率与标签对照词典”里查询,就可以轻松完成标注了。
以上是针对单个词汇的标签。当研究由两个词组成的复合标签时(比如“缓慢下降”),团队发现了数据集中隐藏的亮点。原来,还可量化“缓慢”(slow)或“快速”(fast)这样的副词对“下降”(decreasing)等动词所产生的影响。
比如,“下降”(decreasing)的平均斜率是 -1.4,但如果是“缓慢下降”(slow decreasing),平均斜率会变得更缓和,为 -0.5;而“快速下降”(fast decreasing)的斜率则更陡峭,为-2.5。
可见,“缓慢”和“快速”就像是数值的“修饰符”一样,可预期地改变基础词汇的斜率。
👉 更有趣的是,这种现象其实与日常语言习惯完全一致。比如,你更希望银行卡余额是“缓慢缩水”而非“快速蒸发”?作家们是希望读者对新书有“温和的”反应,还是“热烈的”反响?
这些修饰词能以有意义的方式在语义和数值上改变基本词汇,从而让句子含义更贴切地反映背后的数据。正因如此,这种更高的精准度使语言描述更贴合数据本质,从而提升决策有效性。
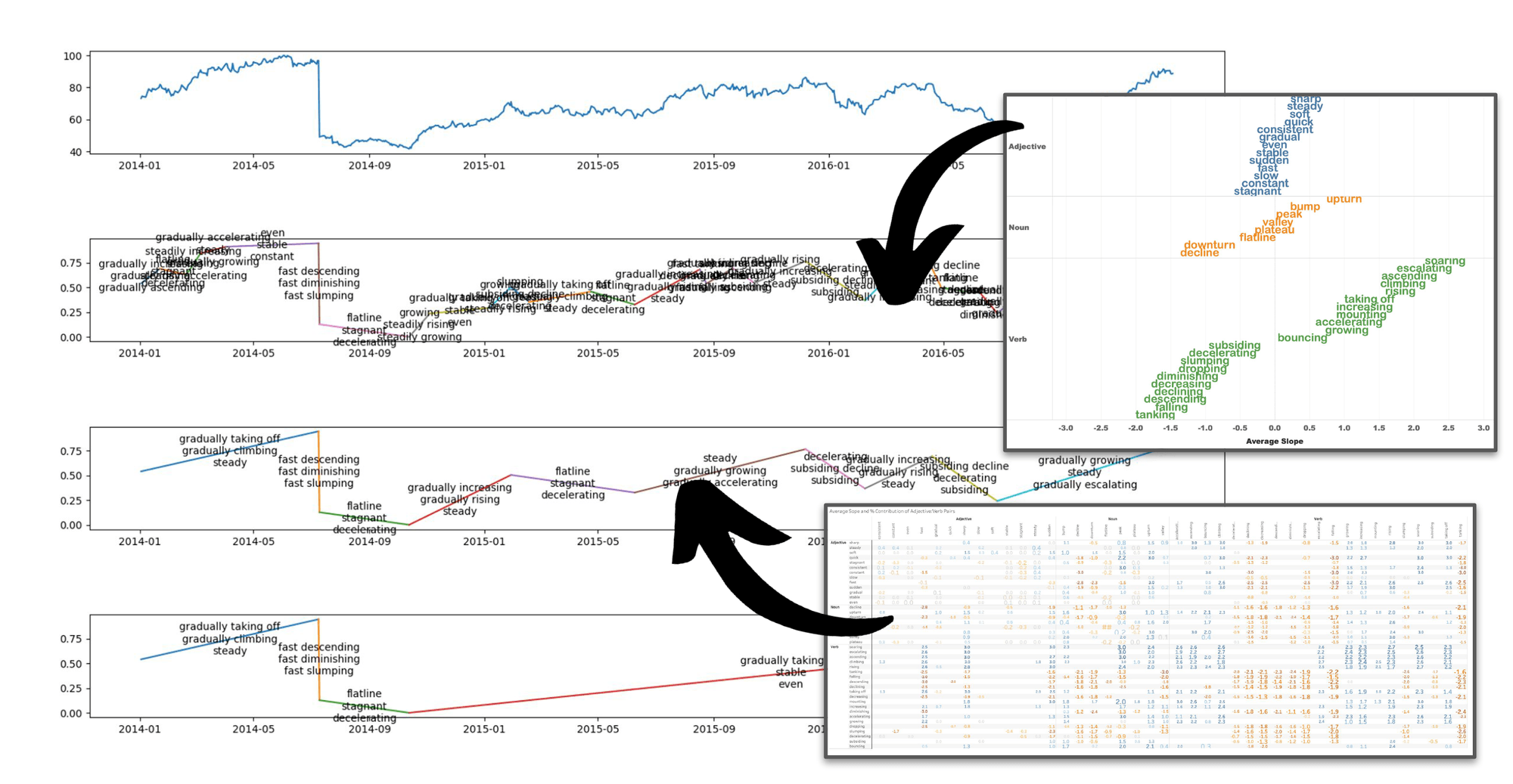
图6:基于斜率进行语义标注的示意图(箭头表示标注位置)
建立单标签与复合标签的斜率对照词典后,Tableau 研究团队开始采用 Ramer-Douglas-Peuker 算法对时间序列数据进行多线段拆分。
如上图,他们以三种粒度将输入数据(顶部)进行划分,以便识别数据中细微、中等和显著的斜率区域。这样,就很容易计算每个线段的斜率,并通过查询词典来完成标注了。
到底是在“瞎折腾”,还是真有用?
折腾了这么久,就是为了告诉我们股票跌了 80% 叫作“断崖式下跌”?你可能会认为,部分结论显而易见,直接根据主观感受来贴几个标签不就行了吗?
但是,Tableau 研究团队的方法确实有独到之处:
👉 首先,标注工具收集回来的标签数据,本质是通用字符串,与任何语言种类无关。我们完全可以用普通话、粤语、日语、法语收集数据,甚至可以用乱码或涂鸦符号。关键在于,不同语言在描述数据时存在细微感知差异,简单翻译英文数据集可能丢失母语者特有的语义层次。
👉 其次,这个方法与具体领域也无关。在本次尝试中,研究团队选用了一些日常通用词汇进行研究。但实际上,这种方法同样适用于医疗数据、金融数据等垂直领域。特定行业的从业者使用专业术语描述现象时,同样可以量化这些领域的专属词汇。
👉 此外,形态与斜率的定义源自大众标注,反映出的是群体认知而非个别开发者的主观判断。当我们需要与不同背景的用户沟通时,这种群体智慧尤为重要。
👉 更重要的是,这项研究确实实现了对自然语言中某种通用语义领域的量化!这不仅非常有趣,也为未来更多、更深入的研究和应用打开了一扇新的大门。
所以,接下来有什么计划?
展望未来,Tableau 研究团队的探索方向非常广阔。最直观的路径自然是现有成果的延伸,比如提升标注精度、扩充标签库、进军细分领域。
但他们野心不止步于折线图,如何将这套方法论迁移到柱状图、饼图甚至是空间地图?能否不依赖图表直接应用?又能否用于解释机器学习模型与 AI Agents 的决策逻辑?
照目前的 Tableau 最新产品路线(比如 Pulse 指标洞察)来看,他们已经开始将“量化语义”框架赋能大语言模型。大语言模型本就是语言与数据的交汇点,这种融合可谓天作之合。
如下图所示,大语言模型(LLM)已能巧妙融合斜率与形态信息,生成语义精准的叙述(虽然会偶然出现事实性幻觉)。值得欣喜的是,模型在遵循新语义规则的同时,仍保持着语言生成的魔力。随着 LLM 与 AI 智能体的进化,相信这种协同效应将愈发显著。
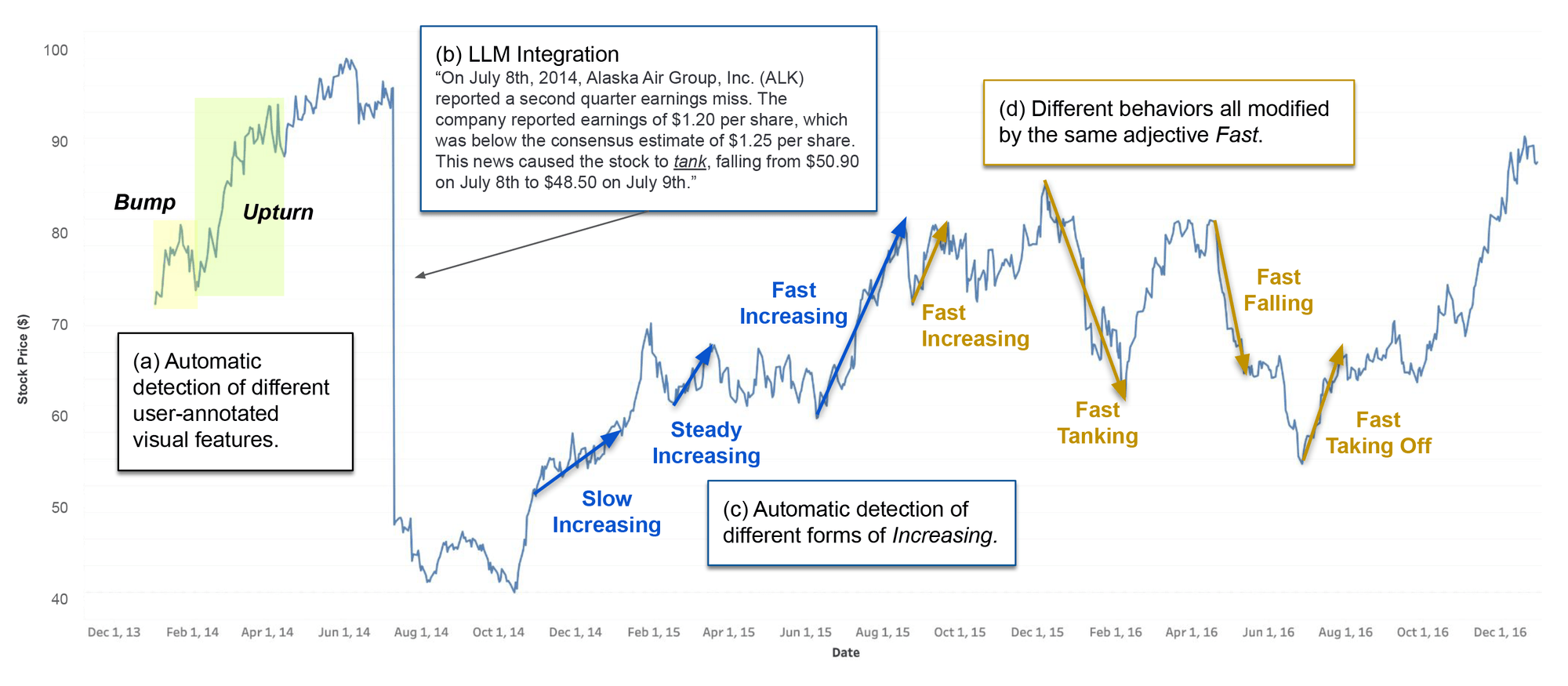
图7:视觉特征语义标注的量化方法
上图显示了如何自动标注折线图中的视觉特征:
(a) 自动检测用户标记的视觉特征;
(b) 将检测出的视觉特征与大型语言模型(LLM)相结合;
(c, d) 基于量化的语义方法自动为趋势中的上升或下降进行标注;这些标注使用“形容词-动词”的搭配方式,体现了实际测算的折线斜率信息,从而生成相应的描述。
👉 如果对这项研究感兴趣,可通过点击此网址观看完整的论文报告。